
A multifaceted book recommendation system leveraging wisdom of the crowds for style critiques.
What makes for good (non-fiction) books, and how do you find them? Genre and subject on their own appears to be the eminent modus operandi for recommendations everywhere you look, from the shelves of your local bookstore to carefully curated Goodreads lists. I have found this methodology to be fundamentally broken. If you wanted to know about something purely based off its informative contents you would go read a Wikipedia article, not a book. This approach feels to me so obviously flawed because it misses the point, which is to read a compelling story that keeps you engaged while learning valuable information on the subject – yet you don’t want to go too far, or you’ll end up with those dreadful 90% fluff popcorn books which could’ve had been easily summarised in a few pages.
Is there a way to bake this in the default approach in which you search for books? Yes, we will make it right here.
We will explore new dimensions like writing style, information transmission effectiveness, depth, and narrative structure. To get these from a variety of perspectives, we’ll use a small subset of a dataset of history & biography books from Goodreads which includes all of the freeform text reviews from the readers, which allows us to tap into something of a wisdom of the crowds phenomenon (wisdom of the critics?)
Because this is 2023, we’ll approach this as RAG-assisted task with some critical tweaks which allows us to pool millions of reviews cohesively. The main components of the system will work as follows:
- A high-level embeddings books index that captures the description given by the publisher, which allows to narrow down a subpopulation of books based on a theme.
- A broker that randomly pools a sample of 50 reviews for each book, then uses that sample to infer reader-perceived style, narrative structure, etc.
- A reranker that evaluates the most fitting recommendations based on the user query.
- A nice simple interface.
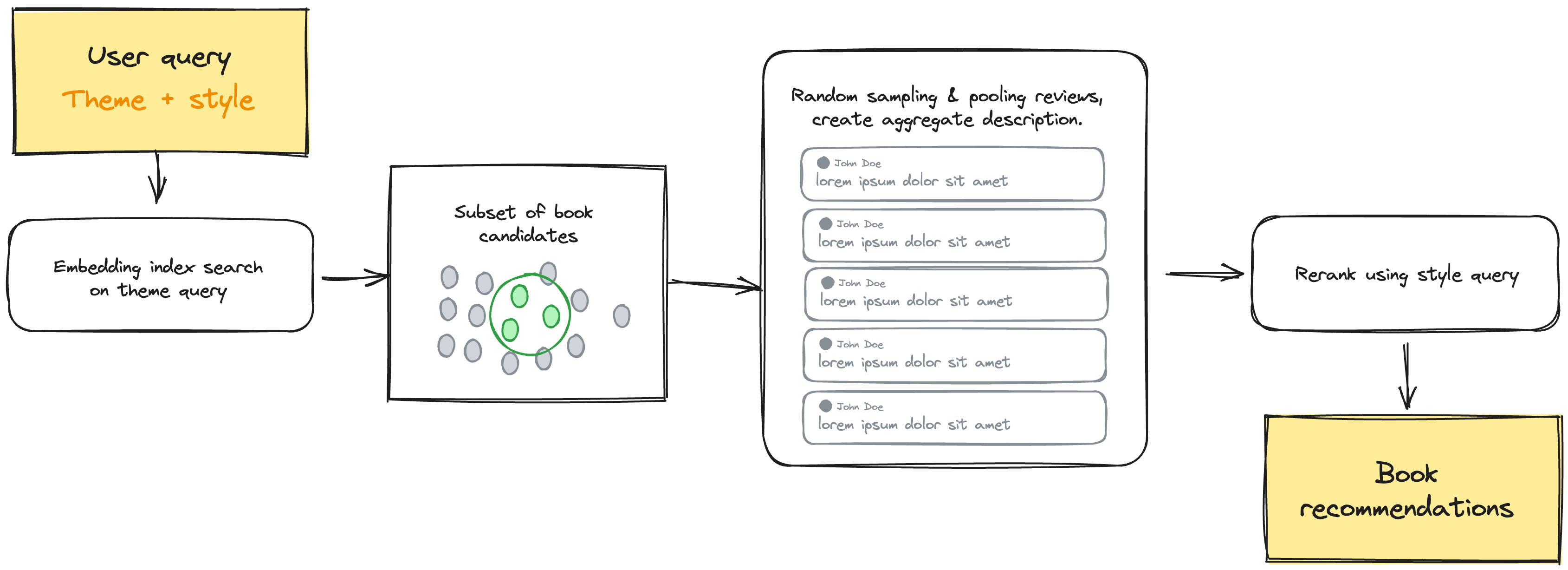
The diagram is pretty self explanatory, most work done was on preprocessing the data, trying out tweaks to the prompting mechanisms, and hosting the different steps on the different providers to guarantee they work in a streamlined fashion. Both the broker and reranker are LLM powered agents that’ll run ad-hoc in order to avoid having to spend a lot of resources on pre-computing everything, which would be faster when querying but not really necessary for this.
The book embedding index is hosted on MongoDB atlas vector search, while the millions of reviews are also hosted on a regular Mongo cluster as well. The pooling and aggregation of the reviews is done by parallel calls to Mixtral-8x7B-Instruct-v0.1 with a simple system prompt that condenses all the opinions in the manner we want. The style reranking step is provided by the cohere rerank endpoint.
One last critical step is balancing all of our different metrics into a single, easy-to-understand confidence score so the user knows how fitting the recommendations are. For this we'll come up with a weighted computation across theme similarity, style similarity, and amount of reviews sampled (we are more certain that a critique is "correct" if it comes from a larger amount of readers, ie. wisdom of the crowds).
where: wtheme = 0.4 (weight for theme similarity), wstyle = 0.4 (weight for style similarity), wreviews = 0.2 (weight for the number of reviews), dtheme = 1 (normalisation denominator), dstyle = 1 (normalisation denominator), dreviews = 50 (normalisation denominator, which takes the max number of reviews we sample).
Now we can try a query like theme = "Attainment of political power during the middle ages" and style = "Short and concise chapters, direct to the point." and we get something like this:
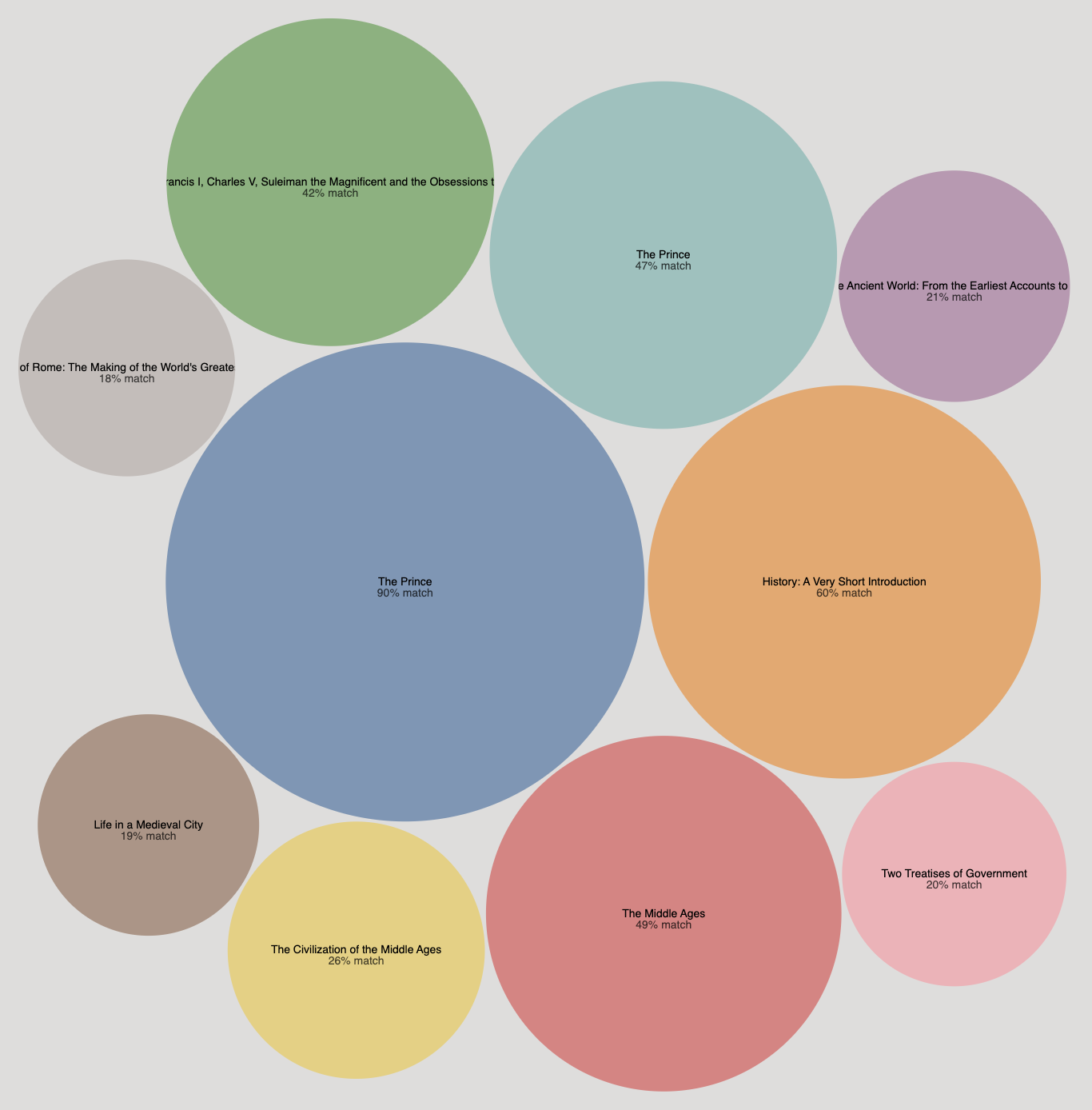
Of course this is a very simple query to demonstrate how it works and for very well-known books you could simply ask ChatGPT (given they are highly represented in the training data); the power of this approach relies on grounded, real-time, crowd-sourced information which helps uncover not-so-famous and newer books.
This prototype system is deployed and functional and you can try it out here